Создание эффективных агентов¶
Мы работали с десятками команд, создающих LLM-агентов в различных отраслях. Последовательно, наиболее успешные реализации используют простые, компонуемые паттерны, а не сложные фреймворки.
Примеры кода
В примерах кода используется AI SDK, работающий в Durable Objects.
За последний год мы работали с десятками команд, создающих агентов на основе больших языковых моделей (LLM) в различных отраслях. Последовательно, наиболее успешные реализации не использовали сложные фреймворки или специализированные библиотеки. Вместо этого они строились с использованием простых, компонуемых паттернов.
В этом посте мы делимся тем, что узнали из работы с нашими клиентами и создания агентов самостоятельно, и даем практические советы разработчикам по созданию эффективных агентов.
Что такое агенты?¶
"Агент" можно определить несколькими способами. Некоторые клиенты определяют агентов как полностью автономные системы, которые работают независимо в течение длительных периодов времени, используя различные инструменты для выполнения сложных задач. Другие используют этот термин для описания более предписывающих реализаций, следующих заранее определенным рабочим процессам. В Anthropic мы классифицируем все эти варианты как агентные системы, но проводим важное архитектурное различие между рабочими процессами (workflows) и агентами:
- Рабочие процессы — это системы, где LLM и инструменты организованы через заранее определенные пути кода.
- Агенты, с другой стороны, — это системы, где LLM динамически направляют свои собственные процессы и использование инструментов, сохраняя контроль над тем, как они выполняют задачи.
Ниже мы подробно рассмотрим оба типа агентных систем. В Приложении 1 ("Агенты на практике") мы описываем две области, где клиенты нашли особую ценность в использовании таких систем.
Когда (и когда не) использовать агентов¶
При создании приложений с LLM мы рекомендуем искать максимально простое решение и увеличивать сложность только при необходимости. Это может означать, что агентные системы вообще не нужны. Агентные системы часто обменивают задержку и стоимость на лучшую производительность задач, и вы должны учитывать, когда такой компромисс имеет смысл.
Когда большая сложность оправдана, рабочие процессы обеспечивают предсказуемость и последовательность для четко определенных задач, в то время как агенты являются лучшим вариантом, когда нужна гибкость и принятие решений на основе модели в масштабе. Однако для многих приложений оптимизация одиночных вызовов LLM с извлечением данных и примерами в контексте обычно достаточна.
Когда и как использовать фреймворки¶
Существует множество фреймворков, которые упрощают реализацию агентных систем, включая:
- LangGraph от LangChain;
- AI Agent framework от Amazon Bedrock;
- Rivet — конструктор рабочих процессов LLM с графическим интерфейсом перетаскивания; и
- Vellum — еще один графический инструмент для создания и тестирования сложных рабочих процессов.
Эти фреймворки облегчают начало работы, упрощая стандартные низкоуровневые задачи, такие как вызов LLM, определение и анализ инструментов, а также объединение вызовов в цепочки. Однако они часто создают дополнительные слои абстракции, которые могут скрывать базовые промпты и ответы, делая их сложнее в отладке. Они также могут соблазнять добавлять сложность, когда более простая настройка была бы достаточной.
Мы предлагаем разработчикам начинать с прямого использования API LLM: многие паттерны можно реализовать всего в несколько строк кода. Если вы все же используете фреймворк, убедитесь, что понимаете базовый код. Неправильные предположения о том, что происходит под капотом, являются распространенным источником ошибок клиентов.
Смотрите нашу кулинарную книгу для примеров реализаций.
Строительные блоки, рабочие процессы и агенты¶
В этом разделе мы рассмотрим распространенные паттерны агентных систем, которые мы наблюдали в продакшене. Мы начнем с нашего фундаментального строительного блока — дополненного LLM — и постепенно увеличим сложность, от простых композиционных рабочих процессов до автономных агентов.
Строительный блок: Дополненный LLM¶
Основным строительным блоком агентных систем является LLM, дополненный такими возможностями, как извлечение данных, инструменты и память. Наши текущие модели могут активно использовать эти возможности — генерировать собственные поисковые запросы, выбирать подходящие инструменты и определять, какую информацию сохранять.
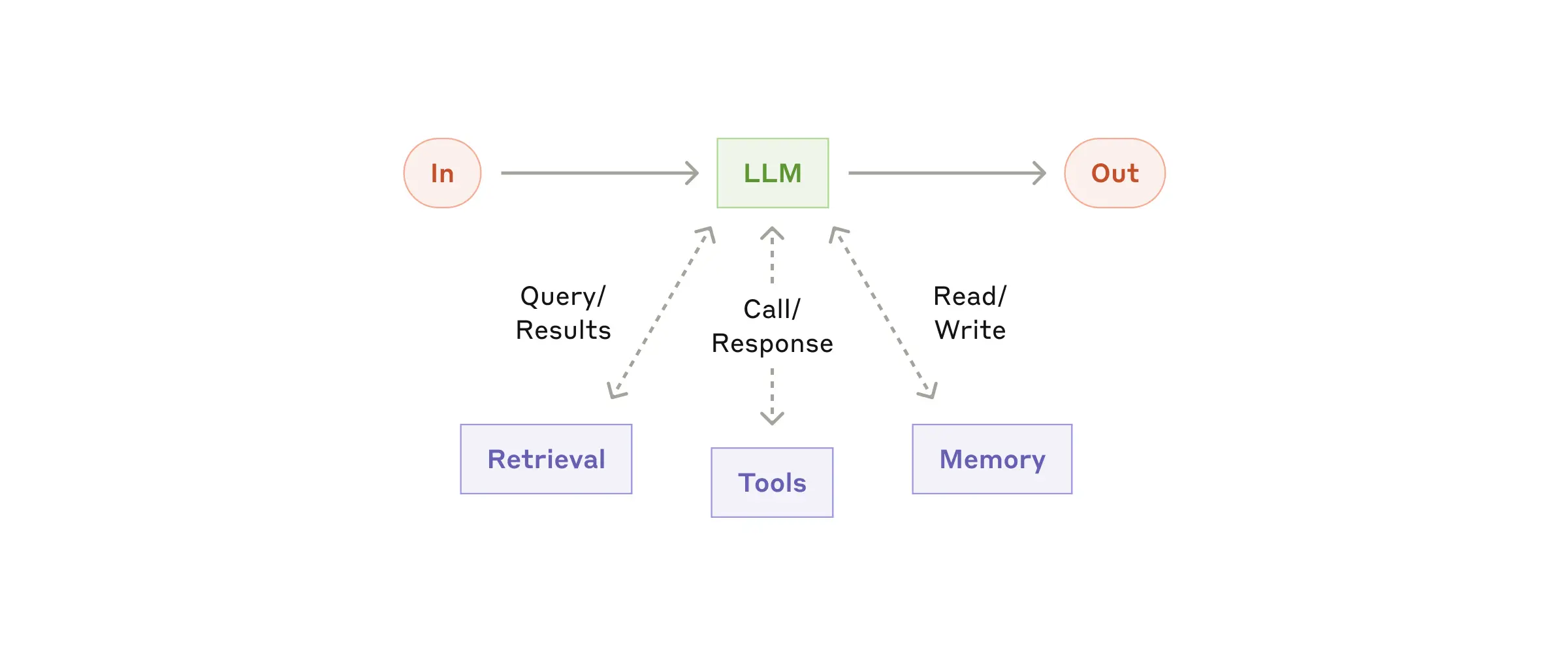
Мы рекомендуем сосредоточиться на двух ключевых аспектах реализации: адаптации этих возможностей под ваш конкретный случай использования и обеспечении простого, хорошо документированного интерфейса для вашего LLM. Хотя существует множество способов реализации этих дополнений, один из подходов — использование нашего недавно выпущенного Model Context Protocol, который позволяет разработчикам интегрироваться с растущей экосистемой сторонних инструментов с помощью простой реализации клиента.
В оставшейся части этого поста мы предполагаем, что каждый вызов LLM имеет доступ к этим дополненным возможностям.
Рабочий процесс: Цепочка промптов¶
Цепочка промптов разбивает задачу на последовательность шагов, где каждый вызов LLM обрабатывает выходные данные предыдущего. Вы можете добавить программные проверки (см. "шлюз" на диаграмме ниже) на любые промежуточные шаги, чтобы убедиться, что процесс все еще на правильном пути.
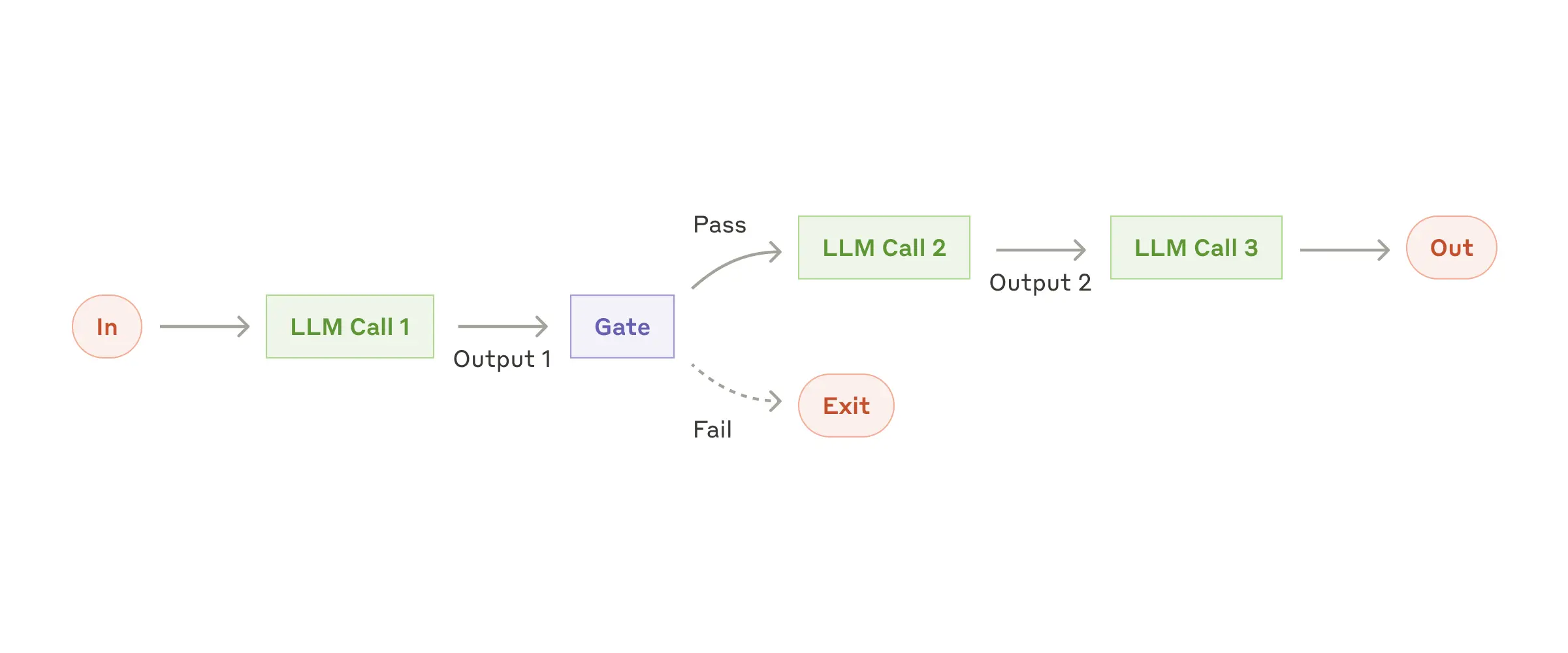
Когда использовать этот рабочий процесс: Этот рабочий процесс идеален для ситуаций, когда задачу можно легко и четко разложить на фиксированные подзадачи. Основная цель — обменять задержку на более высокую точность, сделав каждый вызов LLM более простой задачей.
Примеры, где полезна цепочка промптов:
- Создание маркетингового текста, а затем его перевод на другой язык.
- Написание плана документа, проверка того, что план соответствует определенным критериям, а затем написание документа на основе плана.
Рабочий процесс: Маршрутизация¶
Маршрутизация классифицирует входные данные и направляет их на специализированную последующую задачу. Этот рабочий процесс позволяет разделить ответственность и создавать более специализированные промпты. Без этого рабочего процесса оптимизация для одного типа входных данных может ухудшить производительность для других входных данных.
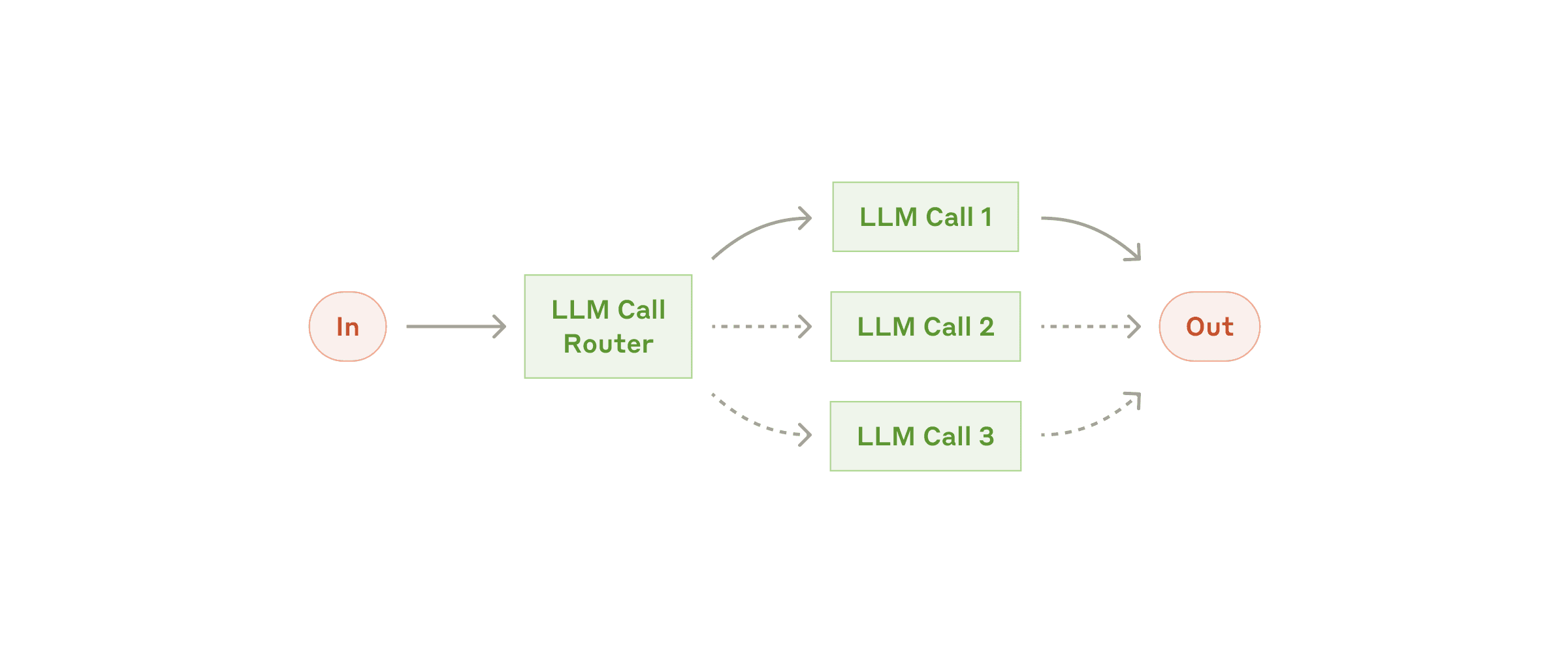
Когда использовать этот рабочий процесс: Маршрутизация хорошо работает для сложных задач, где есть четкие категории, которые лучше обрабатывать отдельно, и где классификация может быть выполнена точно либо LLM, либо более традиционной моделью/алгоритмом классификации.
Примеры, где полезна маршрутизация:
- Направление различных типов запросов в службу поддержки клиентов (общие вопросы, запросы на возврат средств, техническая поддержка) в различные последующие процессы, промпты и инструменты.
- Маршрутизация простых/распространенных вопросов к меньшим, экономичным моделям вроде Claude Haiku 4.5 и сложных/необычных вопросов к более мощным моделям вроде Claude Sonnet 4.5 для оптимизации производительности.
Рабочий процесс: Параллелизация¶
LLM иногда могут работать одновременно над задачей, а их выходные данные агрегируются программно. Этот рабочий процесс, параллелизация, проявляется в двух ключевых вариациях:
- Секционирование: Разбиение задачи на независимые подзадачи, выполняемые параллельно.
- Голосование: Запуск одной и той же задачи несколько раз для получения разнообразных выходных данных.
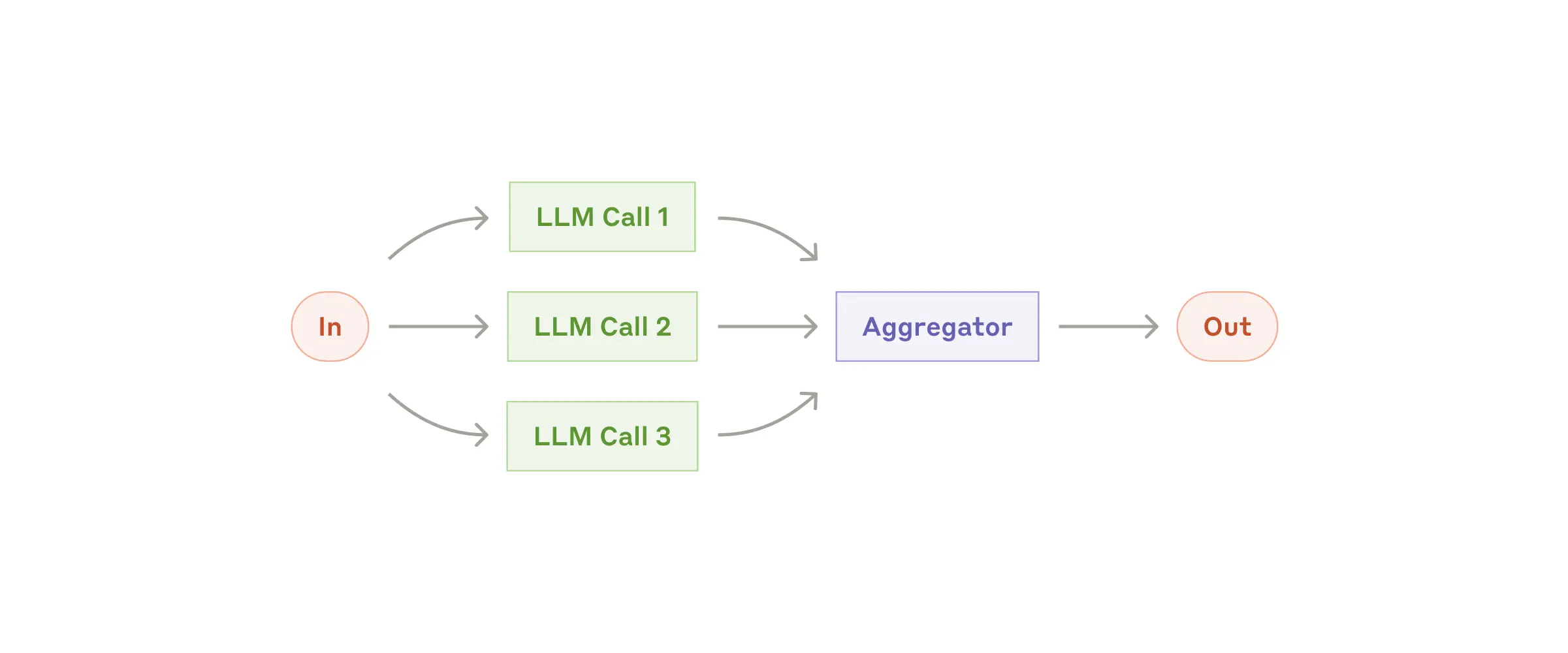
Когда использовать этот рабочий процесс: Параллелизация эффективна, когда разделенные подзадачи могут быть параллелизованы для скорости, или когда нужны несколько точек зрения или попыток для результатов с более высокой уверенностью. Для сложных задач с множеством соображений LLM обычно работают лучше, когда каждое соображение обрабатывается отдельным вызовом LLM, позволяя сосредоточенное внимание на каждом конкретном аспекте.
Примеры, где полезна параллелизация:
- Секционирование:
- Реализация защитных механизмов, где один экземпляр модели обрабатывает пользовательские запросы, в то время как другой проверяет их на наличие неподходящего содержимого или запросов. Это обычно работает лучше, чем когда один и тот же вызов LLM обрабатывает как защитные механизмы, так и основной ответ.
- Автоматизация оценок для оценки производительности LLM, где каждый вызов LLM оценивает различный аспект производительности модели по данному промпту.
- Голосование:
- Проверка кода на наличие уязвимостей, где несколько различных промптов проверяют и помечают код, если находят проблему.
- Оценка того, является ли данный фрагмент контента неподходящим, с использованием нескольких промптов для оценки различных аспектов или требующих различных порогов голосования для баланса ложных срабатываний и пропусков.
Рабочий процесс: Оркестратор-работники¶
В рабочем процессе оркестратор-работники центральный LLM динамически разбивает задачи, делегирует их рабочим LLM и синтезирует их результаты.
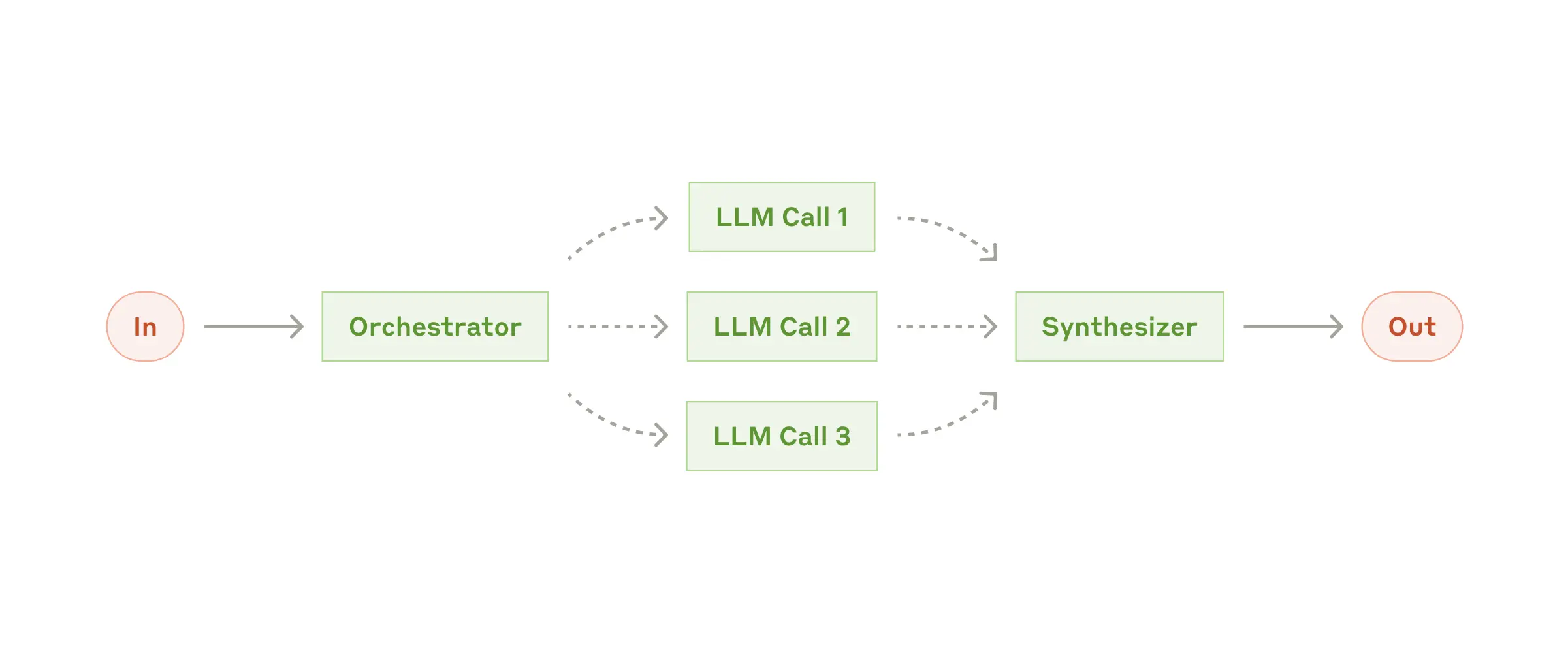
Когда использовать этот рабочий процесс: Этот рабочий процесс хорошо подходит для сложных задач, где вы не можете предсказать необходимые подзадачи (например, в кодировании количество файлов, которые нужно изменить, и характер изменений в каждом файле, вероятно, зависят от задачи). Хотя он топографически похож, ключевое отличие от параллелизации — его гибкость: подзадачи не предопределены, а определяются оркестратором на основе конкретного входа.
Пример, где полезен оркестратор-работники:
- Продукты для кодирования, которые каждый раз вносят сложные изменения в несколько файлов.
- Поисковые задачи, которые включают сбор и анализ информации из нескольких источников для возможной релевантной информации.
Рабочий процесс: Оценщик-оптимизатор¶
В рабочем процессе оценщик-оптимизатор один вызов LLM генерирует ответ, в то время как другой предоставляет оценку и обратную связь в цикле.
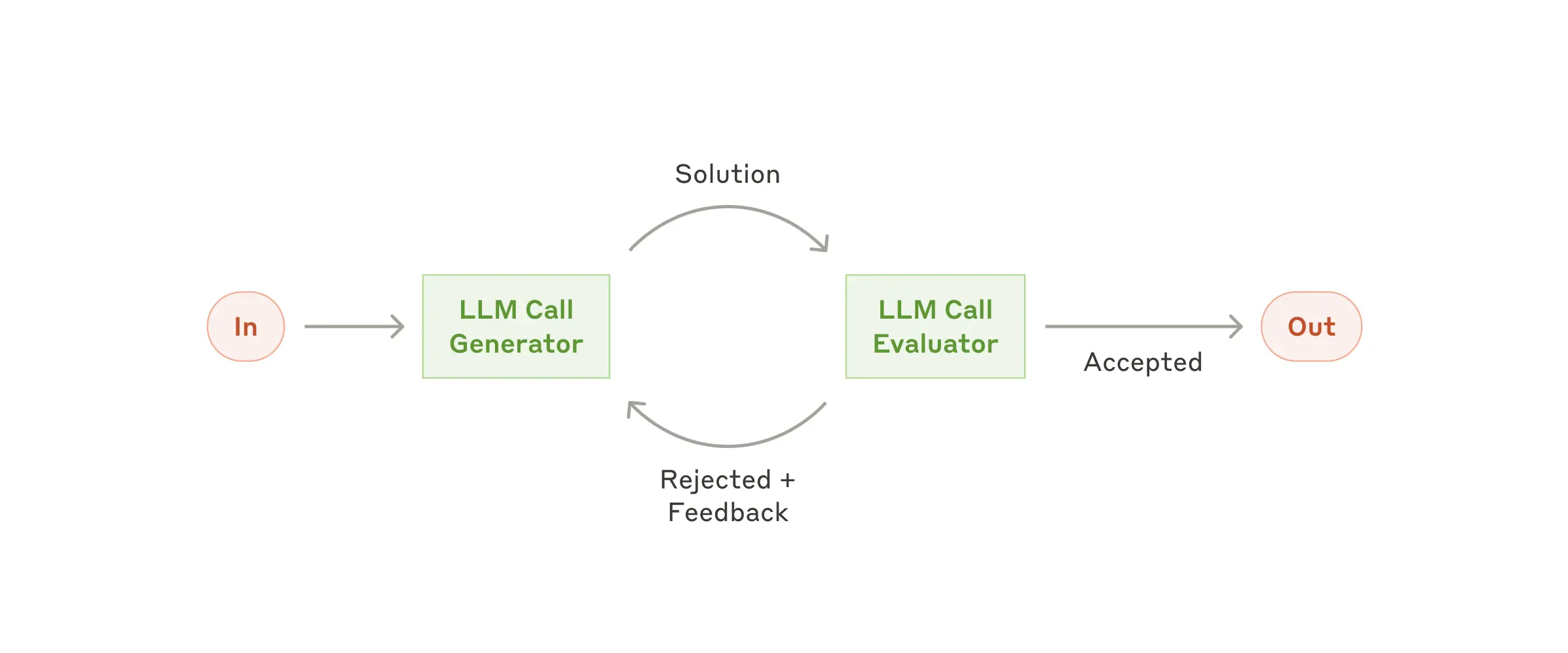
Когда использовать этот рабочий процесс: Этот рабочий процесс особенно эффективен, когда у нас есть четкие критерии оценки, и когда итеративное уточнение дает измеримую ценность. Два признака хорошего соответствия: во-первых, ответы LLM могут быть demonstrably улучшены, когда человек формулирует свою обратную связь; и во-вторых, LLM может предоставить такую обратную связь. Это аналогично итеративному процессу письма, через который может пройти человеческий писатель при создании отполированного документа.
Примеры, где полезен оценщик-оптимизатор:
- Литературный перевод, где есть нюансы, которые LLM-переводчик может не уловить изначально, но где LLM-оценщик может предоставить полезную критику.
- Сложные поисковые задачи, которые требуют нескольких раундов поиска и анализа для сбора всесторонней информации, где оценщик решает, нужны ли дальнейшие поиски.
Агенты¶
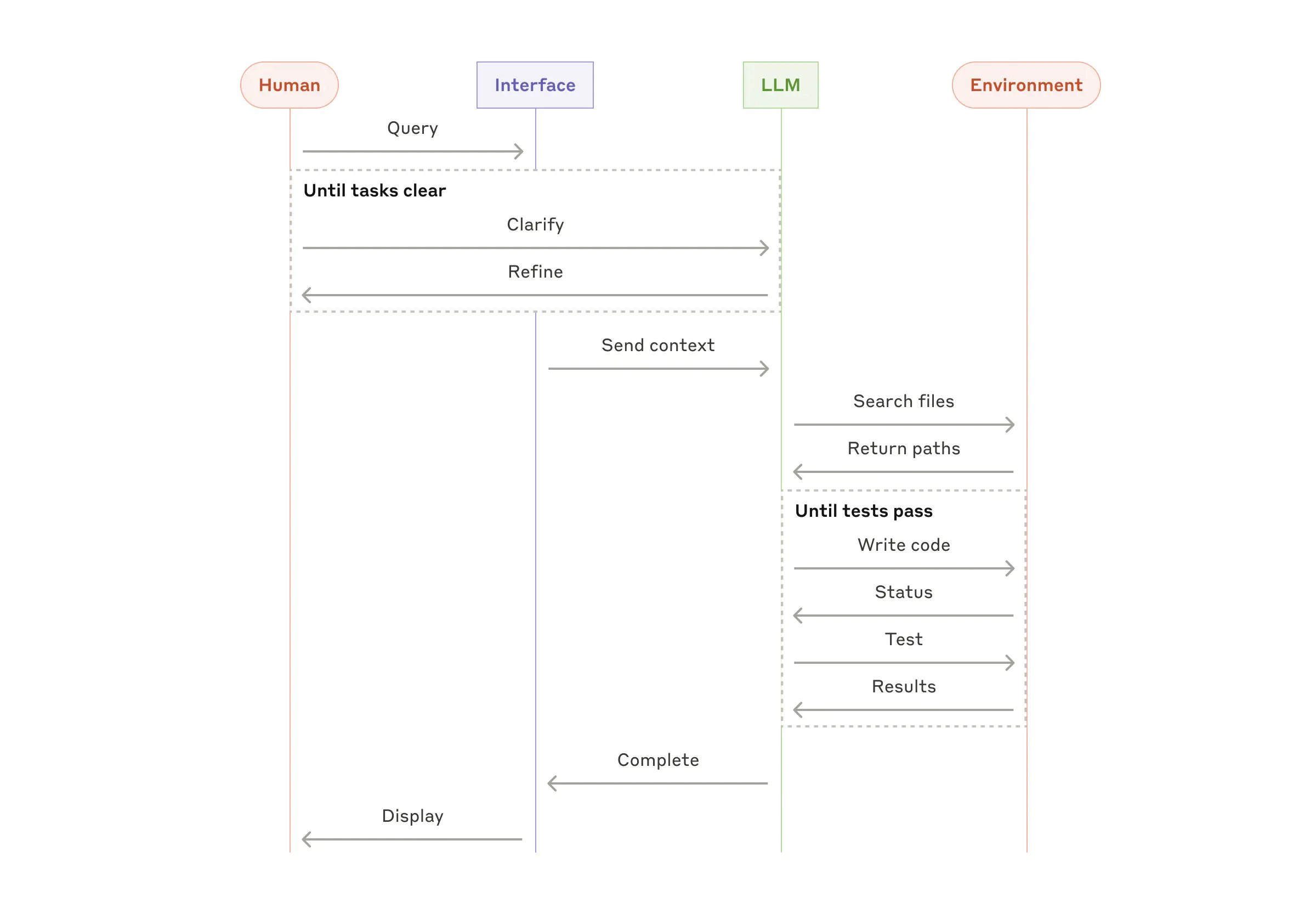
Агенты появляются в продакшене по мере созревания LLM в ключевых возможностях — понимании сложных входных данных, вовлечении в рассуждения и планирование, надежном использовании инструментов и восстановлении после ошибок. Агенты начинают свою работу либо с команды от человека, либо с интерактивного обсуждения с пользователем. Как только задача становится ясной, агенты планируют и работают независимо, потенциально возвращаясь к человеку за дополнительной информацией или суждением. Во время выполнения крайне важно, чтобы агенты получали "фактическую истину" из окружающей среды на каждом шаге (например, результаты вызовов инструментов или выполнения кода) для оценки своего прогресса. Агенты могут затем приостановиться для обратной связи от человека на контрольных точках или при столкновении с препятствиями. Задача часто завершается по завершении, но также распространено включение условий остановки (например, максимальное количество итераций) для поддержания контроля.
Агенты могут обрабатывать сложные задачи, но их реализация часто проста. Они обычно представляют собой просто LLM, использующие инструменты на основе обратной связи от окружающей среды в цикле. Поэтому крайне важно четко и продуманно проектировать наборы инструментов и их документацию. Мы подробно рассмотрим лучшие практики разработки инструментов в Приложении 2 ("Промпт-инжиниринг ваших инструментов").
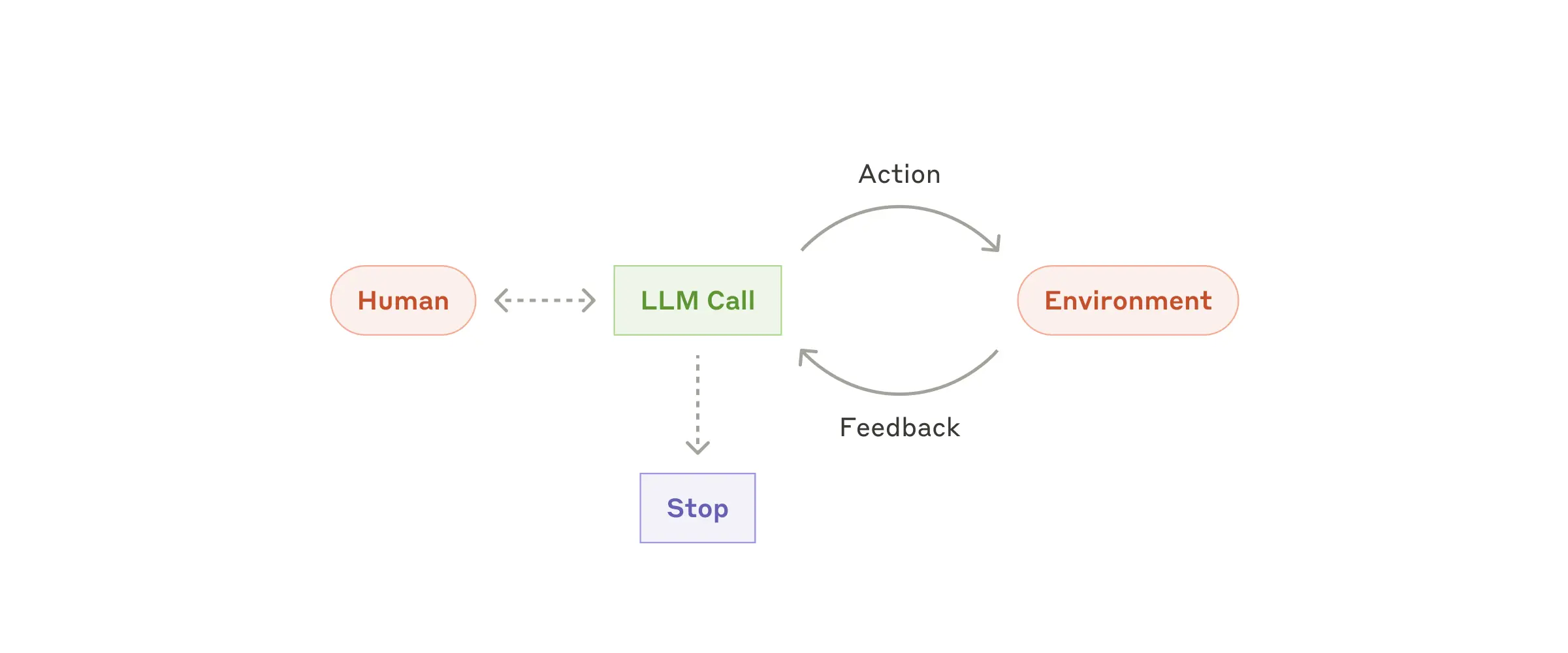
Когда использовать агентов: Агенты могут использоваться для задач с открытым концом, где трудно или невозможно предсказать необходимое количество шагов, и где вы не можете жестко закодировать фиксированный путь. LLM потенциально будет работать в течение многих поворотов, и у вас должен быть определенный уровень доверия к его принятию решений. Автономность агентов делает их идеальными для масштабирования задач в доверенных средах.
Автономная природа агентов означает более высокие затраты и потенциал для накопления ошибок. Мы рекомендуем обширное тестирование в изолированных средах вместе с соответствующими защитными механизмами.
Примеры, где полезны агенты:
Следующие примеры взяты из наших собственных реализаций:
- Агент для кодирования для решения задач SWE-bench, которые включают редактирование множества файлов на основе описания задачи;
- Наша эталонная реализация "использования компьютера", где Claude использует компьютер для выполнения задач.
Комбинирование и настройка этих паттернов¶
Эти строительные блоки не являются предписывающими. Это распространенные паттерны, которые разработчики могут формировать и комбинировать для различных случаев использования. Ключ к успеху, как и для любых функций LLM, — измерение производительности и итерация реализаций. Повторим: вы должны добавлять сложность только когда она demonstrably улучшает результаты.
Резюме¶
Успех в пространстве LLM — это не создание наиболее сложной системы. Это создание правильной системы для ваших нужд. Начинайте с простых промптов, оптимизируйте их с помощью всесторонней оценки и добавляйте многошаговые агентные системы только когда более простые решения недостаточны.
При реализации агентов мы стараемся следовать трем основным принципам:
- Поддерживать простоту в дизайне вашего агента.
- Отдавать приоритет прозрачности, явно показывая шаги планирования агента.
- Тщательно создавать интерфейс агент-компьютер (ACI) через тщательную документацию и тестирование инструментов.
Фреймворки могут помочь вам быстро начать, но не стесняйтесь уменьшать уровни абстракции и строить с базовыми компонентами по мере перехода к продакшену. Следуя этим принципам, вы можете создавать агентов, которые не только мощные, но также надежные, поддерживаемые и доверенные их пользователями.
Благодарности¶
Написано Эриком Шлунцем и Барри Чжаном. Эта работа основана на нашем опыте создания агентов в Anthropic и ценных insights, которыми поделились наши клиенты, за что мы глубоко благодарны.
Приложение 1: Агенты на практике¶
Наша работа с клиентами выявила два особенно перспективных применения ИИ-агентов, которые демонстрируют практическую ценность описанных выше паттернов. Оба применения иллюстрируют, как агенты добавляют наибольшую ценность для задач, которые требуют как разговора, так и действия, имеют четкие критерии успеха, позволяют создавать циклы обратной связи и интегрируют значимый человеческий надзор.
А. Поддержка клиентов¶
Поддержка клиентов сочетает знакомые интерфейсы чатботов с расширенными возможностями через интеграцию инструментов. Это естественное соответствие для более открытых агентов, поскольку:
- Взаимодействия поддержки естественно следуют потоку разговора, требуя доступа к внешней информации и действиям;
- Инструменты могут быть интегрированы для извлечения данных клиентов, истории заказов и статей базы знаний;
- Действия, такие как выдача возвратов или обновление заявок, могут обрабатываться программно; и
- Успех может быть четко измерен через решения, определяемые пользователем.
Несколько компаний продемонстрировали жизнеспособность этого подхода через модели ценообразования на основе использования, которые взимают плату только за успешные решения, показывая уверенность в эффективности своих агентов.
Б. Кодирующие агенты¶
Пространство разработки программного обеспечения показало замечательный потенциал для функций LLM, с возможностями, развивающимися от автодополнения кода до автономного решения проблем. Агенты особенно эффективны, поскольку:
- Решения кода проверяемы через автоматизированные тесты;
- Агенты могут итеративно улучшать решения, используя результаты тестов как обратную связь;
- Проблемное пространство четко определено и структурировано; и
- Качество выходных данных может быть измерено объективно.
В нашей собственной реализации агенты теперь могут решать реальные проблемы GitHub в бенчмарке SWE-bench Verified на основе описания pull request'а. Однако, хотя автоматизированное тестирование помогает проверить функциональность, человеческий обзор остается решающим для обеспечения соответствия решений более широким системным требованиям.
Приложение 2: Промпт-инжиниринг ваших инструментов¶
Независимо от того, какую агентную систему вы создаете, инструменты, вероятно, будут важной частью вашего агента. Инструменты позволяют Claude взаимодействовать с внешними сервисами и API, указывая их точную структуру и определение в нашем API. Когда Claude отвечает, он включит блок использования инструмента в ответ API, если планирует вызвать инструмент. Определениям и спецификациям инструментов следует уделять столько же внимания промпт-инжиниринга, сколько и вашим общим промптам. В этом кратком приложении мы описываем, как проводить промпт-инжиниринг ваших инструментов.
Часто существует несколько способов указать одно и то же действие. Например, вы можете указать редактирование файла, написав diff, или переписав весь файл целиком. Для структурированного вывода вы можете вернуть код внутри markdown или внутри JSON. В программной инженерии такие различия косметичны и могут быть преобразованы без потерь из одного в другой. Однако некоторые форматы гораздо сложнее для LLM писать, чем другие. Написание diff требует знания количества изменяемых строк в заголовке блока перед написанием нового кода. Написание кода внутри JSON (по сравнению с markdown) требует дополнительного экранирования переводов строк и кавычек.
Наши предложения по выбору форматов инструментов следующие:
- Дайте модели достаточно токенов для "размышления", прежде чем она загоняет себя в угол.
- Держите формат близким к тому, что модель видела естественно встречающимся в тексте в интернете.
- Убедитесь, что нет накладных расходов форматирования, таких как необходимость вести точный учет тысяч строк кода или экранирование строк любого кода, который она пишет.
Одно правило большого пальца — подумать о том, сколько усилий уходит на интерфейсы человек-компьютер (HCI), и планировать инвестировать столько же усилий в создание хороших интерфейсов агент-компьютер (ACI). Вот некоторые мысли о том, как это сделать:
- Поставьте себя на место модели. Очевидно ли, как использовать этот инструмент, на основе описания и параметров, или вам нужно подумать об этом внимательно? Если да, то это, вероятно, верно и для модели. Хорошее определение инструмента часто включает примеры использования, крайние случаи, требования к формату входных данных и четкие границы с другими инструментами.
- Как вы можете изменить названия параметров или описания, чтобы сделать вещи более очевидными? Думайте об этом как о написании отличной строки документации для младшего разработчика в вашей команде. Это особенно важно при использовании многих похожих инструментов.
- Тестируйте, как модель использует ваши инструменты: Запускайте множество примеров входных данных в нашей workbench, чтобы увидеть, какие ошибки делает модель, и итеративно улучшайте.
- Poka-yoke ваши инструменты. Измените аргументы так, чтобы было сложнее допустить ошибки.
При создании нашего агента для SWE-bench мы фактически потратили больше времени на оптимизацию наших инструментов, чем на общий промпт. Например, мы обнаружили, что модель делала ошибки с инструментами, использующими относительные пути к файлам после того, как агент вышел из корневого каталога. Чтобы исправить это, мы изменили инструмент, чтобы он всегда требовал абсолютные пути к файлам — и мы обнаружили, что модель использовала этот метод безупречно.
Источники: